Ever since ChatGPT made large language models (LLMs) accessible to people and businesses, innovation has been moving at the speed of light. In just two years, artificial intelligence (AI) has gone from a curiosity to an expectation, fueled by real-world advancements from companies like OpenAI and Anthropic, and reshaping how products are built, tested, and decisions are made.
But as AI becomes more integral to how we work, two questions keep surfacing: can we trust it, and what role should it play? For researchers, those aren’t theoretical questions. Their craft depends on accuracy, context, and deep human judgment; the very things AI systems are often benchmarked against, and frequently challenged on.
From the beginning, we never set out to replace researchers or reinvent research with machines. We set out to protect what makes research valuable through thoughtful questioning, human context, and depth, while making it easier to run and repeat. We wanted to build something that felt like a real teammate to researchers—capable, trustworthy, and always ready to help. That’s how our AI moderator came to life: an always-on AI research partner designed to deliver interview-depth insights at scale.
So, let’s take a look under the hood at what it takes to build an AI moderator that researchers can trust.
Research-grade AI in practice
Research-grade AI isn’t about novelty, but about reliability in real-world conditions. For us, research-grade AI isn’t a destination—it’s a standard we hold ourselves to as the technology evolves.
While recent advancements in artificial intelligence have unlocked powerful new capabilities, not every AI system is built to handle the complexity, nuance, and accountability that research demands. In AI research, progress is often measured by outputs and how consistently systems perform across diverse, real-world scenarios, especially when human judgment is involved.
The first challenge for us was building a tool that meets the same standards and best practices as a skilled human researcher. That meant asking high-quality, unbiased, and focused questions—and following up in ways that feel natural, curious, and deep. We approached this with a set of guiding principles that shape every interaction.
AI grounded in a researcher’s mindset
Our AI moderator approaches studies the same way a researcher would. It doesn't chase answers; instead, it aims to uncover meaningful insights. It starts by understanding the goals behind each study and structures the conversation to deliver insights that inform product and business decisions.
Unlike generic AI that requires constant prompting, our moderator understands researcher workflows by design. It suggests question types, identifies potential bias, and guides conversations towards the kind of insights that hold up in stakeholder presentations. It knows when to dig deeper, when to pivot conversations, and connects the dots across participants. It even sets the right tone—greeting participants to get them comfortable, framing the context, and thanking them for their time.
This distinction matters because modern AI models—particularly large language models—are often optimized for fluency rather than understanding. They’re excellent at producing convincing responses, but without the right mental model, they can miss context, introduce bias, or oversimplify complex tasks. Research-grade AI requires something different: adaptive problem-solving rooted in intent, not just language.
No two studies are the same, so our moderator is guided by a dynamic system of prompts and guardrails that adapts across contexts, from competitive analysis to jobs-to-be-done research. Every prompt is grounded in the researcher’s study goals, so analysis becomes a strategic synthesis.
Let’s look at an example of a pricing study
A generic AI agent might ask:
“Would you say this price feels expensive or affordable?”
Maze’s AI moderator instead digs deeper:
- “Walk me through what you were thinking when you first saw the price”
- “What made it feel that way?”
- “How does this compare to alternatives you’ve used?”
This example is where many AI agents fall short. Without a clear understanding of research goals, AI-driven systems can default to surface-level questioning, which is efficient but not insightful. By anchoring every interaction to context and intent, the moderator behaves less like a scripted interview and more like a human expert navigating ambiguity in real time.
The difference is subtle but fundamental—one chases answers, the other uncovers reasoning researchers can stand behind.

AI that’s rigorous, consistent, and tested
In AI research, rigor is often established through benchmarks, standardized ways of evaluating performance across models and tasks. But research quality can’t be reduced to a single score.
Once we built the moderator, we held it to the same standards and scrutiny that researchers hold on their own work. Across 25 quality metrics—ranging from goal alignment to conversation management—we tested, refined, and retested. We also ran a beta with 35 customers, including global auto manufacturers, B2B payroll processing companies, and B2C retailers, letting human researchers stress-test the moderator against their professional standards, not just technical ones.
To make sure quality held up, we evaluated performance across multiple LLMs, we switched AI models as they evolved, and ran thousands of synthetic sessions to catch edge cases. This kind of evaluation mirrors how AI is tested in fields like robotics, where systems must perform reliably across unpredictable environments, not just controlled demos. For example:
- Sequential questioning: Initially, we found that the moderator occasionally asked follow-ups too mechanically. Reworking the prompts fixed the behavior and improved the quality of the questions
- Overly verbose responses: We noticed this caused participant disengagement and short responses. Adjusting prompts restored natural conversation flow, insights, and sentiment
AI agents can often paraphrase participants, introducing interpretation before analysis begins:
Participant: “I usually open three or four tabs because I can’t find what I need.”
AI might reframe: “It sounds like the navigation is frustrating.”
Our AI moderator is built to listen, probe, and ask:
“Got it. What are you usually trying to find when you open those tabs?”
No commentary, no praise, no nudging. Every follow-up is guided by the researcher’s goals, not scripts. It stays with the participant when depth matters, and moves on once the insight is complete.
AI that scales beyond human limits
Reaching a research-grade quality bar wasn’t the end goal; it was the starting point. Once the moderator consistently met the standards we expect from rigorous human-led research, we turned to the question of scale: how could it help researchers go further than they could on their own?
One of the most immediate answers was language. Maze’s AI moderator now works across 20 languages, making it possible to run high-quality research with global audiences and capture insights in participants’ native tongues.
And this bar isn’t fixed. As models improve and research practices evolve, our team continues to test, refine, and raise our standards so the moderator doesn’t just scale research, but scales it responsibly and ethically.

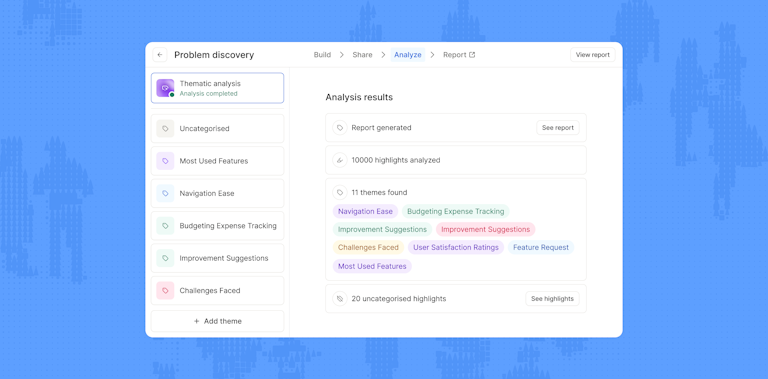
Trust, transparency, and control
Trust has always been central to Maze, long before AI systems entered the conversation. When we set out to democratize research, we learned early on that access alone isn’t enough. For research to scale responsibly, teams need confidence in the work they produce and in the insights they take forward to their team, stakeholders, and ultimately, their customers. Trust isn’t optional; it’s the foundation everything is built on.
Today, that foundation matters more than ever. As generative tools become mainstream, with 58% of product teams already using AI tools, and machine learning models now a regular part of research workflows, adoption has moved quickly. But confidence doesn’t come from usage alone. For researchers, trust comes from knowing how insights are generated, why conclusions are drawn, and when to step in with human judgment.
So we built our AI moderator with trust at its core. From day one, our focus has been on transparency and control. Even with guardrails in place, researchers deserve full visibility into the process and the ability to guide it. Flexible levers throughout the workflow let teams decide when to automate and when to stay hands-on—without ever giving up ownership of their work.
After all, democratizing research only works when researchers trust their tools.
Flexible workflows
Researchers can control the AI moderator’s work as much or as little as they want. From context to goals to questions, everything is editable, keeping the researcher in the driver’s seat. As an example, researchers can add up to five questions per goal, or leave the fields empty (we’ve found that 20% of our users already do) and let AI autonomously explore the goal to collect relevant insights based on each participant's experiences.

Transparent and previewable
When we ran our own research before building the AI moderator, researchers told us how much they care about users’ perception of their product and company. So we gave researchers complete transparency and the ability to validate the moderator’s behavior before it reaches their users.
Before a study launches, researchers can step into the participant’s shoes. It gives them the chance to check the flow, clarity, tone, and ensure the moderator listens, probes, and guides appropriately. This preview gives confidence that the outputs from AI accurately represent both the research and the brand.
Full traceability
After a study, every AI-generated insight can be traced back to the exact moment when participants' responses and original questions are asked. Nothing is hidden, and researchers always retain final control over themes, sentiments, and conclusions.
It’s hard to think that something went wrong when we were able to get the 10 interviews without using any people hours or any work hours like today. That’s jaw-dropping
E-commerce, UX Manager
Speeding up time-to-insights
Research moves fast, but only if insights are delivered efficiently. That’s the challenge many researchers know too well: every “time-saving” tool risks becoming another thing to manage and validate. We designed our AI moderator to solve that problem—giving researchers their time back without compromising rigor.
With the AI moderator, the median time from study creation to actionable insight is just 2.5 days. That includes automated thematic analysis, thoughtfully designed in collaboration with Caitlin Sullivan, a trusted research leader and AI advisor whose guidance helped shape prompts that surface meaningful, nuanced insights.
Faster analysis isn't better unless it's as good as what a senior researcher could do—that's the bar the team is holding themselves to, and it's the right one. The prompts we worked on together were designed to catch nuance and depth, not just high-level codes and categories. For teams trying to move faster without sacrificing insight quality, that's the hard part to get right, and Maze is doing it.


Caitlin Sullivan
AI Advisor and Trainer
Share
Automating analysis doesn’t mean removing rigor. Behind the scenes, the system continuously evaluates patterns, compares outputs, and applies consistent logic across studies—something that’s difficult to maintain manually at scale. The result is faster synthesis without sacrificing depth, especially for teams working across multiple markets and timelines.
Reports are generated automatically, too—including highlight reels of real participant quotes, so teams can see the voices behind the data without lifting a finger. Every insight is synthesized and mapped to your research goals, making it easy to integrate with other studies and analyze in the Maze platform.
It’s research at full speed; efficient, reliable, and built to free up researchers for the work that truly requires human judgment.
Building the study was super easy. It took 15 minutes to complete, probably less. I’m a bit of a perfectionist, but it probably could have taken 5 minutes.
Networking, Researcher

The inevitable future of research
The future of AI in research isn’t about replacing humans; it’s about giving teams the tools to move faster, dig deeper, and act smarter. Product managers can validate ideas in hours instead of weeks, designers can test across 20 languages to uncover cultural nuances, and marketers can capture real-world perceptions through conversations instead of rigid rating scales. Research becomes the competitive advantage that separates leaders from followers.
We’re stepping into a world where insights flow directly into product roadmaps, customer voices are embedded in every strategic decision, and user-centricity is operationalized across organizations. This transformation of an AI-driven world is already happening. Companies using our AI moderator are moving from reactive research to proactive insight generation.
And here’s the thing: as AI evolves, capability alone won’t be the differentiator. Trust will. Accountability will. And so will knowing how to blend AI with human judgment. The most impactful systems won’t replace judgment—they’ll extend it, helping teams solve more complex problems faster, across increasingly complex environments.
The question is no longer whether AI will transform research—it’s whether you’re ready.